2026. 1. 9. 19:34ㆍQGIS
KOSIS에서 제공하는 주관적 건강 인식 수준 자료는 시·군·구 단위로 집계되어 있다. 그러나 해당 자료를 하위 행정구역 수준의 공간 분석에 그대로 적용할 경우, 하나의 기초자치단체 내부가 전부 동질적인 공간이라는 강한 가정을 전제하게 된다. 이는 특히 동일한 기초자치단체 안에 도시 지역과 농촌 지역이 혼재되어 있거나, 지역 내부의 사회경제적 격차가 큰 경우에 심각한 문제를 야기할 수 있다. 이러한 상황에서는 주관적 건강 인식 수준의 공간적 분포가 실제보다 과도하게 단순화되며, 그 결과 분석 결과의 해석 가능성과 정책적 활용 가능성이 모두 저하될 우려가 크다. 또한 낮은 해상도의 데이터는 위생시설, 녹지, 대기오염, 공장 입지, 삼림 분포 등 래스터 데이터의 형태로 제공되는 공간 데이터와 결합되어 사용되었을 때, 서로 다른 공간 해상도 간의 불일치로 인해 정보 손실이나 분석 결과의 왜곡을 초래할 가능성이 높다.
이러한 한계를 극복하기 위해서는 시·군·구 단위로 관측된 주관적 건강 인식 수준을 하위 행정구역 단위로 재구성하거나 추정하는 과정이 필요하다. 그러나 주관적 건강 인식은 개인의 인식과 사회적 맥락에 기반한 지표로서 물리적 변수와의 직접적인 연관성이 크지 않다. 또한 보건·환경 관련 데이터는 대부분 시·군·구 단위로 측정되어 있어 보조 변수로 활용할 고해상도의 데이터를 얻는 것이 매우 어렵기 때문에, 일반적인 회귀 기반 추정이나 머신러닝 기법을 적용하는 데 이론적·방법론적 제약이 발생한다.
위의 한계를 감안하여, 하위 행정구역의 값을 직접적으로 예측하기보다는, 시·군·구 단위로 제공되는 주관적 건강 인식 수준을 하위 행정구역 분석에 적용할 수 있는 몇 가지 현실적인 방법을 검토하였다. 구체적으로는 상위 행정구역 값을 하위 행정구역에 동일하게 부여하는 단순 지역보간을 출발점으로 하고, 인접 지역 간 유사성을 고려한 공간 스무딩 방법을 추가적으로 적용하여 공간 패턴의 차이를 살펴보고자 한다.

상위 행정구역에서 관측된 값을 해당 행정구역에 포함된 모든 하위 행정구역에 동일하게 할당하는 방법이다. 이 방식은 하위 행정구역 차원에서 활용 가능한 보조 변수가 존재하지 않는 상황에서 적용할 수 있는 가장 단순하면서도 보수적인 다운스케일링 전략에 해당한다. 별도의 추정이나 가중 과정을 거치지 않고 상위 행정구역의 관측값을 그대로 재배치하기 때문에, 추가적인 가정을 최소화한다는 장점이 있다.
다만 이 방법은 하나의 시·군·구 내부에 속한 모든 읍·면·동이 동일한 주관적 건강 인식 수준을 가진다는 강한 동질성 가정을 전제로 한다. 따라서 하위 행정구역 간의 실제 공간적 이질성이나 지역 내부의 사회경제적 격차를 반영하지 못하며, 결과적으로 하위 행정구역 단위의 미시적인 공간 패턴은 드러나지 않는다. 이러한 특성으로 인해 하위 행정구역 수준의 주관적 건강 인식 분포를 정밀하게 예측하거나, 지역 내부의 차이를 분석하는 데에는 한계가 있다.
그럼에도 불구하고 이 방법은 상위 행정구역 자료가 내포하고 있는 공간적 정보를 왜곡 없이 하위 행정구역 분석에 활용하고자 할 때 유용하다. 즉, 하위 행정구역 간의 차이를 인위적으로 생성하기보다는, 상위 단위 자료의 해상도를 낮은 가정 수준에서 재표현하는 데 목적이 있을 경우 적절한 선택이 될 수 있다. 그러나 제기된 문제 상황, 즉 기초자치단체 내부의 공간적 이질성과 사회적 격차를 보다 구체적으로 드러내는 데에는 해결 능력이 제한적이라는 점에서, 다른 보완적 방법과의 비교가 필요하다.

인접 지역 평균 기반 스무딩은 각 하위 행정구역의 값이 주변에 위치한 이웃 지역들의 값과 유사할 것이라는 직관적인 가정에서 출발한 방법이다. 즉, 특정 읍·면·동의 주관적 건강 인식 수준은 해당 지역 자체의 값뿐만 아니라, 공간적으로 인접한 읍·면·동들의 평균적인 수준을 함께 반영하여 결정된다고 본다. 이러한 접근은 공간적으로 인접한 지역 간에는 유사한 특성이 나타날 가능성이 높다는 공간 자기상관의 개념에 기반한다. 구체적으로는 읍·면·동 벡터 데이터의 중심점을 계산한 뒤, 중심점 간의 거리 또는 인접 관계를 기준으로 이웃 지역을 정의한다. 이후 각 읍·면·동에 대해, 사전에 정의된 이웃 지역들의 주관적 건강 인식 수준을 평균하여 새로운 값을 산출하거나, 기존 값과 이웃 평균을 결합한 형태의 값을 계산한다. 이때 핵심은 거리에 비례하여 값을 보간하는 것이 아니라, 일정 기준에 따라 선택된 이웃 지역들의 값을 평균화함으로써 공간적 연속성을 완화된 형태로 반영하는 데 있다.
이 방법은 단순 지역보간과 달리, 동일한 시·군·구 내부에 속하더라도 하위 행정구역 간에 완전히 동일한 값을 부여하지 않으며, 인접 지역 간의 공간적 관계를 고려함으로써 보다 부드러운 공간 패턴을 생성할 수 있다는 장점이 있다. 또한 보조 변수가 충분하지 않은 상황에서도 적용 가능하다는 점에서, 하위 행정구역 단위 분석을 위한 현실적인 대안으로 활용될 수 있다.
반면, 인접 지역 평균 기반 스무딩은 하위 행정구역 간의 실제 차이를 설명하는 요인을 직접적으로 반영하지는 못한다. 이웃 지역과의 공간적 관계만을 정보로 활용하기 때문에, 스무딩 과정에서 국지적인 극값이 완화되거나 실제 존재하는 지역 간 차이가 일부 희석될 수 있다. 따라서 이 방법은 하위 행정구역의 주관적 건강 인식 수준을 정밀하게 예측하기보다는, 상위 행정구역 자료를 하위 단위 분석에 적용하는 과정에서 공간적 불연속성을 완화하고, 보다 안정적인 공간 분포를 확인하기 위한 보완적 접근으로 이해하는 것이 적절하

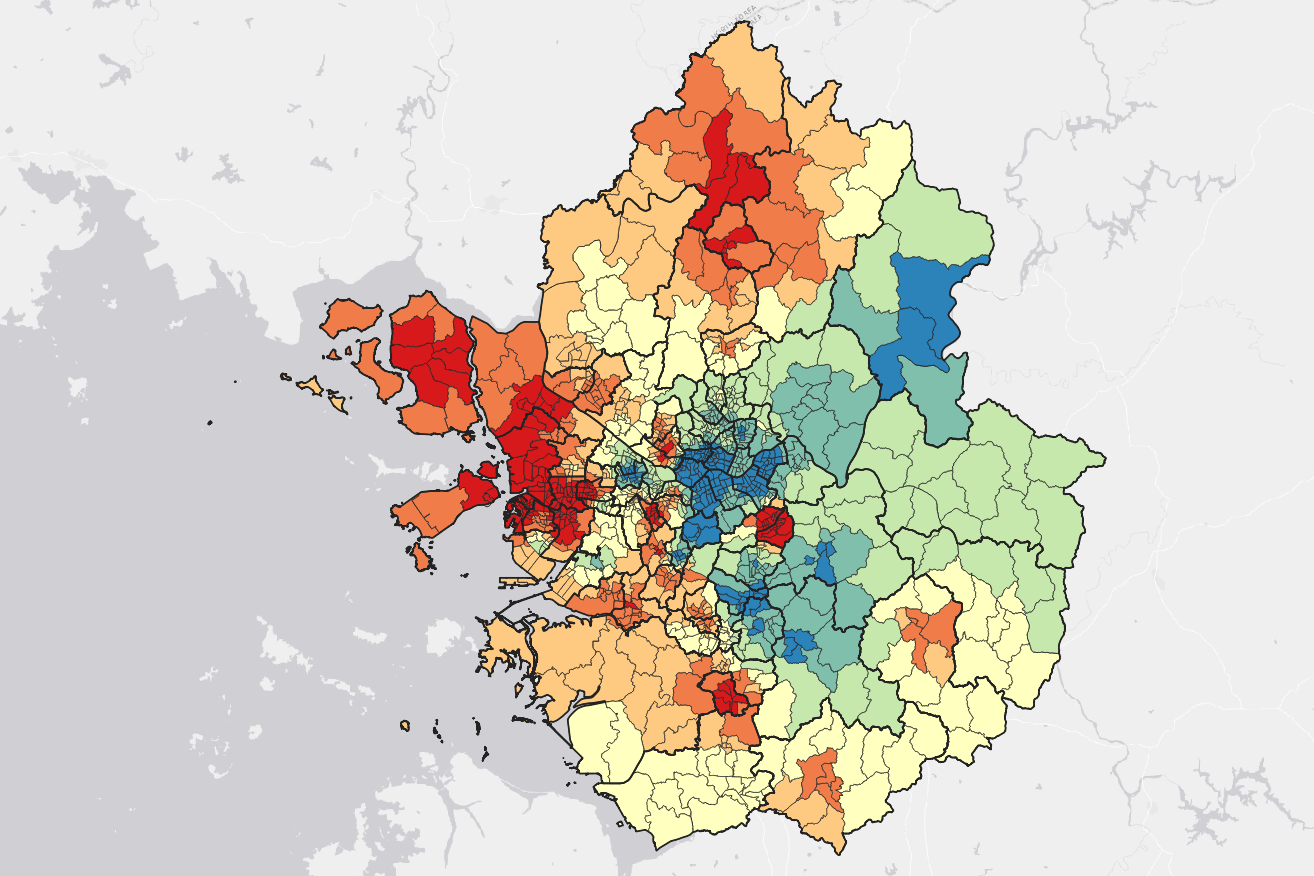

인구가 집중된 지역일수록 해당 지자체의 평균 특성값에 가까운 수치를 보일 것이라는 가정에서 출발한 방법으로, 인구 분포 래스터를 통해 각 시·군·구 별로 인구 중심점을 구하고, 그 인구 중심점을 중심으로 역거리 가중(IDW) 보간을 실시하여 고해상도의 래스터 데이터를 얻은 뒤, 그 데이터를 다시 읍·면·동 단위로 집계하여 공간적 재분포 및 평활화를 수행한 방법이다.
이 방법의 장점은 상위 행정구역 단위로 제공되는 값을 공간적으로 재분포함으로써, 하위 행정구역 내부의 공간적 연속성을 시각적으로 표현할 수 있다는 점에 있다. 특히 인구 분포 래스터와 같은 고해상도 공간 데이터를 활용함으로써, 동일한 시·군·구 내부에서도 인구가 집중된 지역과 그렇지 않은 지역 간에 완만한 공간적 차이를 부여할 수 있으며, 단순 지역보간이나 행정경계 기반 스무딩에 비해 보다 부드러운 공간 패턴을 생성할 수 있다. 또한 결과가 연속적인 래스터 형태로 산출되기 때문에, 대기오염, 녹지 분포 등 다른 환경 요인과의 시각적 비교나 공간적 중첩 분석에 활용하기 용이하다는 장점이 있다.
반면, 이 방법은 인구가 집중된 지역일수록 해당 시·군·구의 평균 특성값에 가까운 값을 가질 것이라는 강한 가정을 전제로 한다는 한계를 가진다. 주관적 건강 인식과 같이 인구 규모나 밀도와의 직접적인 인과관계가 명확하지 않은 지표의 경우, 이러한 가정은 결과 해석에 주의를 요구한다. 특히 인구 분포가 사실상 보조 변수처럼 작동하게 되므로, 공간적 패턴이 실제 건강 인식의 분포라기보다는 인구 구조의 공간적 특성을 반영한 결과로 해석될 위험이 있다.
또한 IDW 보간 과정에서 사용되는 거리계수와 탐색 반경과 같은 하이퍼파라미터를 연구자가 직접 설정해야 한다는 점도 중요한 한계로 작용한다. 이러한 파라미터 선택은 결과의 공간적 패턴에 큰 영향을 미칠 수 있으나, 이를 객관적으로 결정할 명확한 기준이 존재하지 않는 경우가 많다. 그 결과 동일한 자료를 사용하더라도 설정값에 따라 상이한 결과가 도출될 수 있으며, 분석 결과의 재현성과 해석 가능성 측면에서 주의가 필요하다.
'QGIS' 카테고리의 다른 글
| IDW 보간법으로 기온 폴리곤 그리드 만들기 (0) | 2025.11.06 |
|---|---|
| 서울시 내 이디야커피 / 스타벅스 매장 분포 분석 (5) | 2025.06.18 |
| 2SFCA(2 Step Floating Catchment Area) 분석 실습 (0) | 2024.11.02 |
| Isochrone Area (동시간선영역/서비스지역) (0) | 2024.08.01 |
| Globe Builder 플러그인으로 지구본에 나타내기 (0) | 2024.08.01 |