
2024. 8. 1. 21:50ㆍML
사이킷런 패키지에서 머신러닝을 수행하는 모델을 몇가지 정리해 보았습니다.
부정확한 내용이 많습니다.
데이터는 R에서도 많이 사용하는 아이리스를 사용했습니다.
퍼셉트론
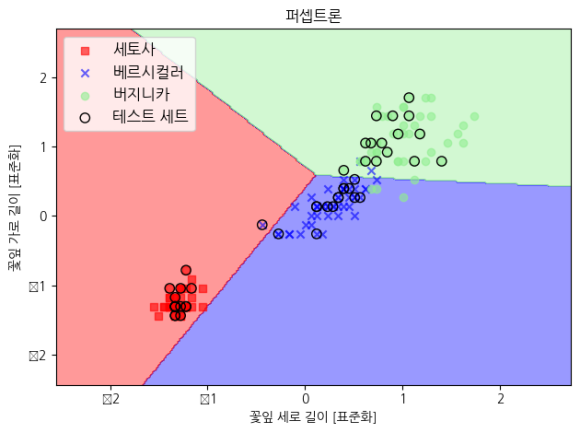
직선의 기울기를 달리하면서 제일 덜 잘못 나누는 선을 구합니다. 뉴런의 출력 결과가 모아니면 도 식(계단처럼 생긴 함수)이기 때문에 막 찍찍 긋는 경향이 있습니다. 우리 할머니보다 6살 어린 오래된 알고리즘입니다.
로지스틱 회귀
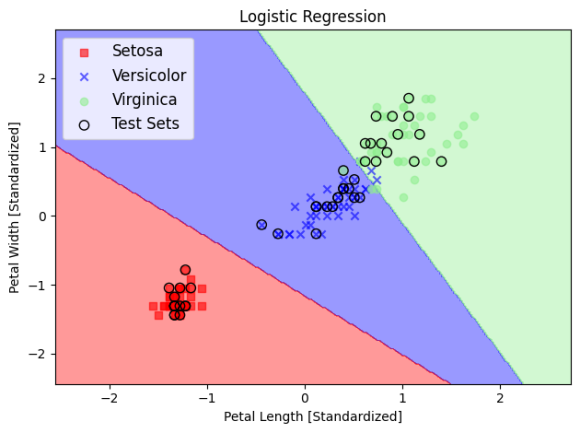
퍼셉트론에서 활성화함수만 시그모이드 함수로 바뀐 것이 로지스틱 회귀입니다. 시그모이드 함수는 계단보다는 좀 더 부드럽게 생긴 로그함수의 일종입니다. 뉴런에서 모 아니면 도라고 결정을 하고 선을 찍찍 긋기 전에 이렇게 긋는게 맞을 확률이 얼마나 될지 한번 더 생각을 하기 때문에 좀 더 잘 분류됩니다. 퍼셉트론이 생각이란 걸 하기 시작했을 뿐인데 왜 회귀라는 이름이 붙는지는 아직 잘 모르겠습니다.
서포트 벡터 머신 (SVM)
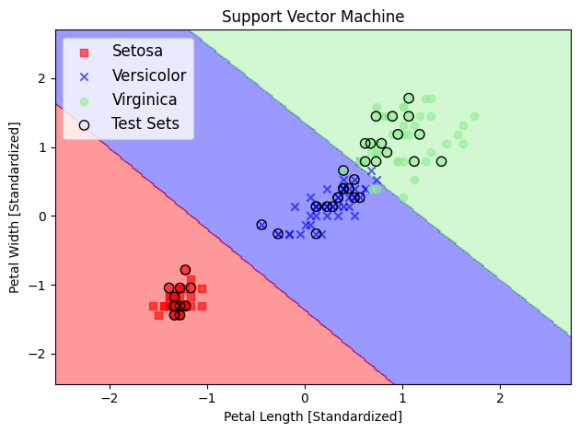
선과 각 샘플 사이의 거리가 최대화되는 직선을 긋습니다. 또한 동시에 슬랙 변수라는 공식을 사용하여 직선을 그을 때 다른 쪽 영토에 샘플을 몇개 버라는 게 최적일지 계산합니다. 여기까지는 퍼셉트론의 단순한 확장이기 때문에 로지스틱 회귀와 비슷합니다.
커널 SVM
2차원 평면에서 직선을 찍찍 긋는건 분류에 한계가 있기 때문에 더 잘 구분하기 위해서 선을 구불구불하게 그릴 필요가 있습니다. 그러기 위해서 저 2차원 평면상의 점들을 잠깐 3차원 공간에 다녀오게 합니다.
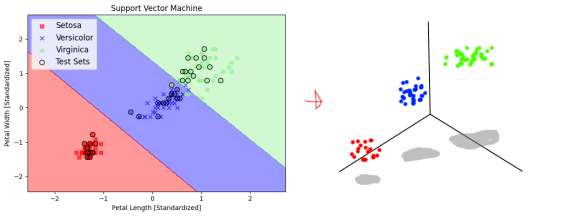
이런 느낌이랄까
2차원 점들을 3차원 공간에서 자르는 방법은 온갖 방법이 있고 우린 그 방법을 생각할 만큼 똑똑하지 않기 때문에 가우스좌의 방사기저함수(RBF)를 적용합니다.
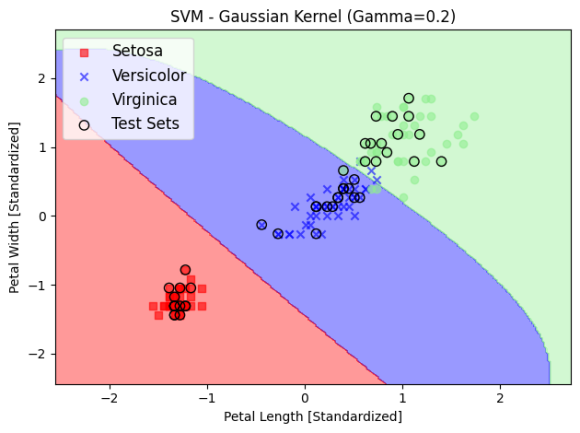
여기에서 3차원 공간에서 각 영토가 차지하는 공간의 울룩불룩한 정도를 결정하는 감마(gamma) 값을 높이면 더 세세하게 분류할 수 있습니다.
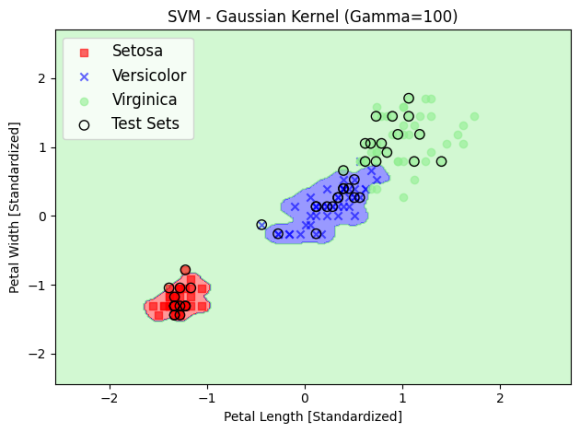
잘 분류한 것 같긴 한데 이렇게 분류하면 모델이 복잡해질 뿐만 아니라 컴퓨터 자원도 무지막지 처먹게 됩니다. 이렇게 알고리즘이 너무 민감해 모델이 지나치게 복잡해지는 것을 과대적합이라고 합니다.
결정 트리
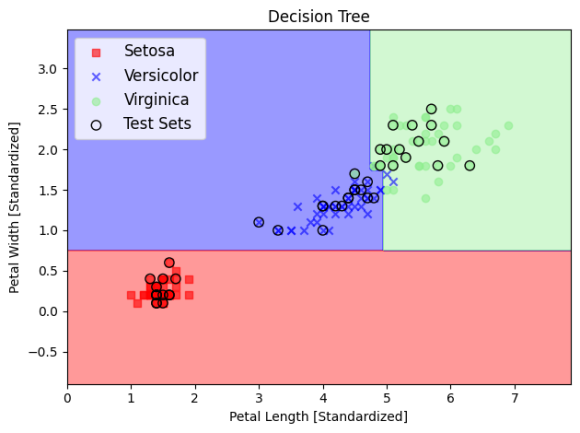
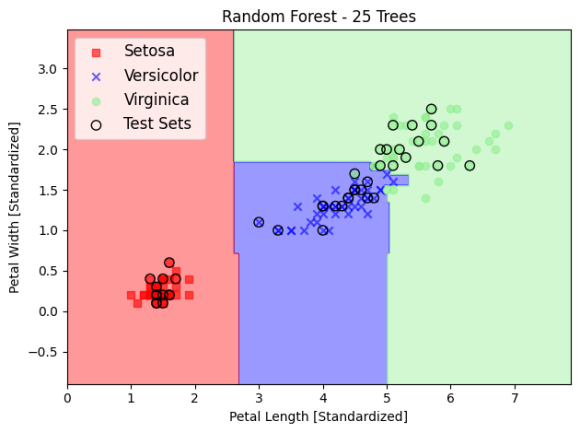
평면을 사각형 격자로 나눠서 이만큼은 이쪽땅 저만큼은 저쪽땅을 의사결정나무로 분류하는 과정입니다. 지니(gini)불순도 조건을 통해 몇 번 나눌지 지정합니다. 위 사진같은 경우는 4번에 걸쳐 평면을 나눈 것입니다. 좀 더 나은 분할을 위해 샘플을 몇개만 뽑아서 땅을 나누고, 이렇게 땅을 나눈 지도 여러개를 겹쳐 평균을 내는 방법을 랜덤 포레스트라고 하는데, 25개 나무를 평균낸 결과는 아래와 같습니다.
K-최근접 이웃
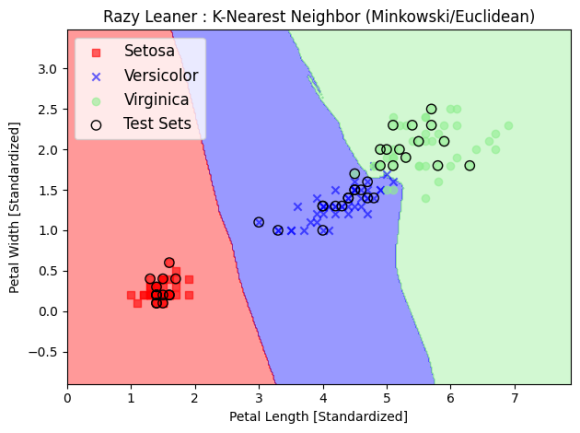
가장 가까운 k개의 가까운 점들을 이은 공간이 어떤 색깔 영토일지를 각 점들끼리의 다수결 투표를 통해 정하는 민주적인(...) 방식입니다. 데이터셋의 차원이 늘어남에 따라 과대적합될 가능성이 높습니다.
'ML' 카테고리의 다른 글
| 그리드 서치로 하이퍼파라미터 튜닝 (0) | 2024.08.12 |
|---|---|
| 데이터 차원 축소를 위한 PCA, LDA, K-PCA (0) | 2024.08.07 |
| 모델 복잡도 제한을 위한 L1 / L2 규제 (1) | 2024.08.03 |